HTTP/2
HTTP/2 Frequently Asked Questions
- HTTP/2 Frequently Asked Questions
- 일반적인 질문
- 왜 HTTP를 개정합니까?
- 누가 HTTP/2를 만들었습니까?
- SPDY와 무슨 관계입니까?
- HTTP/2.0입니까? 아니면 HTTP/2입니까?
- HTTP/1.x와의 주요 차이점은 무엇입니까?
- 왜 HTTP/2는 바이너리를 사용합니까?
- HTTP/2가 다중화되어있는 이유는 무엇입니까?
- 왜 단 하나의 TCP 연결입니까?
- Server Push의 장점은 무엇입니까?
- 헤더 압축이 필요한 이유
- 왜 HPACK입니까?
- HTTP/2에서 쿠키(또는 다른 헤더)를 개선시킬 수 있습니까?
- non-browser HTTP 사용자는 어떻게 되나요?
- HTTP/2는 암호화가 필요합니까?
- HTTP/2는 보안을 개선하기 위해 무엇을 할 것인가?
- 지금 HTTP/2를 사용할 수 있습니까?
- HTTP/2는 HTTP/1.x를 바꾸시겠습니까?
- HTTP/3이 있나요?
- 구현에 관한 질문
- 배치에 관한 질문
- 일반적인 질문
HTTP/2 Frequently Asked Questions
일반적인 질문
왜 HTTP를 개정합니까?
HTTP/1.1은 15 년 이상 Web을 잘 유지해 왔지만, 이젠 오래된 기술이 되어가고 있습니다.
Web 페이지의 로드는 이전보다 자원이 집중되고 있습니다. HTTP 아카이브 페이지 크기 통계 참조 이러한 것들을 효율적으로 로딩하는것은 어렵습니다. 이유는 HTTP는 실제로는 TCP 연결 당 하나의 미처리의 요구 밖에 허용하지 않기 때문입니다.
지금까지 브라우저는 여러 TCP 연결을 사용하여 병렬 요청을 발행했습니다. 그러나 여러 TCP 연결을 허용하는 것에는 한계가 있습니다. TCP 연결이 너무 많으면 역효과를 낳고,(TCP congestion control이 효과적으로 처리하지 못하고 오히려 성능과 네트워크에의 성능에 나쁜 영향을 줍니다.) 근본적으로는 골고루 처리하지 못합니다. (브라우저가 네트워크 리소스보다 많은 점유율을 차지하고 있기 때문입니다).
동시에 다수의 요청이 의미하는 것은 처리 중인 랜선(on the wire)에 중복된 데이터가 많다는 것을 의미합니다.
이러한 요소 모두는 HTTP/1.1 요구에는 그들과 관련된 오버 헤드가 많은 것을 의미합니다. 너무 많은 요청이 발생하면 성능이 저하됩니다.
이에 따라 업계는 Spriting, Data:Inliinininining, domainsharding, concatenation 같은 것을 수행하는 것이 모범 사례가 되어가고 있습니다. 이러한 해킹은 프로토콜 자체의 근저에있는 문제의 징후이며, 사용시에는 많은 문제가 단독으로 발생합니다.
누가 HTTP/2를 만들었습니까?
HTTP/2는 HTTP 프로토콜을 유지하는 IETF 표준 HTTP 워킹 그룹에 의해 개발되었습니다. 이 그룹은 수많은 HTTP를 구했했던 사람들과, 사용자, 네트워크 운영자, HTTP 전문가로 구성되어 있습니다.
메일링리스트는 W3C 사이트에서 호스팅되고 있지만 W3C의 수고는 없습니다. Tim Berners-Lee와 W3C TAG는 WG’s progress로 최신 상태를 유지하고 있습니다.
많은 사람들이 여기에 기여하고자 노력했습니다. 가장 활발한 참가자는 Firefox, Chrome, Twitter, Microsoft의 HTTP 스택, Curl, Akamai 같은 큰 프로젝트 엔지니어와 Python, Ruby, NodeJS와 같은 언어로 HTTP를 구현했던 개발자입니다.
IETF 참여에 대한 자세한 내용은 IETF의 Tao를 참조하시면 됩니다. 누가 이 스펙에 많은 참여를 했는지 확인하시려면 Github’s contributor graph를 참고하시고, Implementations를 확인하시고 싶으시면 implementation list를 참고하시면 됩니다.
SPDY와 무슨 관계입니까?
HTTP/2는 . Mozilla 나 nginx 등의 implementer들이 HTTP/1.x에 상당히 개선시켜서 이끌고 나감에 의해서 SPDY가 명백해졌고 이때 처음 HTTP/2가 논의 되었습니다.
제안서 제출과 선택의 과정을 거친 후, SPDY/2가 HTTP/2의 기반으로 선정되었습니다. 이후 워킹 그룹 토론 및 implementer들의 의견에 따라 일부 변경이있었습니다.
이 과정을 통해 SPDY의 핵심 개발자는 Mike Belshe와 Roberto Peon가 HTTP/2를 개발해왔습니다.
2015년 2월, Google은 HTTP/2를 선택하고, SPDY 지원을 더 이상 하지 않기로 발표했습니다.
HTTP/2.0입니까? 아니면 HTTP/2입니까?
워킹 그룹은 마이너 버전 (“.0”)을 삭제하기로했습니다. 이것은 HTTP/1.x에서 많은 혼란을 초래하고 있기 때문입니다.
즉, HTTP 버전은 기능 세트와 ‘마케팅’이 아닌 와이어의 호환성만을 보여줍니다.
HTTP/1.x와의 주요 차이점은 무엇입니까?
높은 레벨에서의 HTTP/2 :
- 텍스트가 아닌 바이너리입니다.
- 정렬된 blocking 방식 대신에 완전히 다중화되어 있습니다.
- 하나의 연결을 병렬로 사용할 수 있습니다.
- 헤더 압축을 사용하여 오버 헤드를 줄입니다.
- 서버가 클라이언트 캐시에 미리 예방적으로 응답을 “push”할 수 있도록 지원합니다.
왜 HTTP/2는 바이너리를 사용합니까?
바이너리 프로토콜은 HTTP/1.x 같은 텍스트 프로토콜과 비교하여 파싱하는 것이 효율적이고 와이어에(on the wire) 더 컴팩트 합니다. 무엇보다 중요한 것은 오류가 덜 발생하는 경향이 있습니다. 왜냐하면 텍스트는 공백처리, 대소문자, LF/CR 같은 line ending, 빈 줄(blank line) 같은 줄 빈 줄 같은 것을 사용하도록 유도되기(affordances) 때문입니다.
예를 들어 HTTP/1.1 메시지를 파싱하는 4가지 방법이 정의되어 있습니다. HTTP/2는 코드 경로 하나뿐입니다.
HTTP/2는 telnet을 통해 사용할 수 없습니다. 하지만 이미 Wireshark 플러그인 같은 tool들을 지원하고 있습니다.
HTTP/2가 다중화되어있는 이유는 무엇입니까?
HTTP/1.x는 하나의 연결에 대해서 한번의 유효한 요청이 있을 수 있기 때문에 “head-of-line blocking”라는 문제가 있었습니다.
HTTP/1.1에서는 이를 파이프 라인 처리로 해결하려고했지만, 문제(많고, 느린 응답을 처리중에는 그 다음에 온 요청들이 블락될 수 있음)를 완전히 해결할 수 없었습니다. 또한 파이프 라인 처리는 배포하기 매우 어렵습니다. 왜냐하면 많은 중간 매개체와 서버들이 제대로 처리하지 못했기 때문입니다.
이를 통해 클라이언트는 강제로 많은 휴리스틱(보통은 추측해서)를 사용하여 언제 origin 연결을 요청할지 여부를 결정합니다. 페이지가 사용 가능한 연결 수의 10배(또는 그 이상)을 로드하는 것이 일반적이기 때문에 성능에 심각한 영향을 미치고 블락된 요청들은 “waterfall” 문제를 발생 시킬 수 있습니다.
다중화는 여러 요청에 대한 응답 메시지를 동시에 날려줌으로써 이러한 문제를 해결합니다. 하나의 메시지의 일부를 다른 메시지에 섞어서 사용할 수도 있습니다.
이를 통해 클라이언트는 페이지를 로드하기 위해 origin마다 단 하나의 연결만 사용할 수 있습니다.
왜 단 하나의 TCP 연결입니까?
HTTP/1에서는 브라우저는 하나의 origin에서 4~8의 컨넥션을 맺습니다. 많은 사이트가 여러 origin을 사용하기 때문에 1개의 페이지를 로드하는데 30개 이상의 연결이 맺어질 가능성도 있습니다.
하나의 응용 프로그램에서 매우 많은 TCP 연결을 동시에 맺으면 TCP를 설계했던 많은 가정들이 틀려지게 됩니다. 각 연결의 응답에 대해서 엄청난 양의 데이터(flood of data)가 발생하기 시작하기 때문에 중간에 연동하는 네트워크에 버퍼 오버플로 혼잡 이벤트가 발생하게 되고 재전송이 발생하게 될 위험성이 있습니다.
또한 매우 많은 TCP 연결을 사용하는 것은 불공평하게 네트워크 리소스를 독점하고 다른 더 잘 작동하는 응용 프로그램 (예 : VoIP)의 리소스를 훔칩니다(stealing).
Server Push의 장점은 무엇입니까?
브라우저에서 페이지를 요청하면 서버가 응답으로 HTML을 보내고 브라우저가 HTML을 분석하고 모든 embedded assets를 처리한 후에 JavaScript, 이미지, CSS 전송을 시작할 때까지 기다려야 합니다.
서버 푸시는 잠재적으로 클라이언트가 캐시에 필요하다고 생각되는 응답을 “푸시”하여 이 왕복 지연(요청-응답 처리)을 방지 할 수 있습니다.
그러나 푸시 응답은 ‘마법’이 아닙니다. 잘못 사용하면 오히려 성능이 저하 될 수 있습니다. Server Push의 올바른 사용법은 지속적인 시험과 연구가 필요한 영역입니다.
헤더 압축이 필요한 이유
Mozilla의 Patrick McManus는 페이지를 로드 할 때 헤더의 영향에 대한 시간을 계산하여 이를 분명하게 보여주었습니다.
페이지에 80개의 assets가 있다고 가정하면 (요즘으로 치면 일반적인 Web), 각 요청에 대한 헤더는 약 1400 바이트입니다. (자주 Cookie, Referer 등의 해더로 인해). 헤더를 “와이어(on the wire)”에서 온라인으로 오게 하기까지 7~8번의 왕복 처리가 필요합니다. 이것은 응답 시간을 제외하고 클라이언트에서 수신하는 처리입니다.
이것은 TCP의 Slow Start 메커니즘이 원인입니다. 이는 승인된 패킷 수를 기반으로 새로운 연결에서 패킷의 성능을 향상시키고 처음 몇번의 왕복 처리하는 동안 전송할 수 있는 패킷 수를 효과적으로 제한합니다.
이와 비교해서 헤더를 가볍게 압축하면 1회 왕복(아마 1 패킷)만으로도 와이어에 도달 할 수 있습니다.
이러한 오버헤드가 모바일 클라이언트에 미치는 영향을 고려하는 경우에 필요합니다. 모바일 클라이언트는 일반적으로 정상적인 상태에 수백 msec의 왕복 대기 시간이 있습니다.
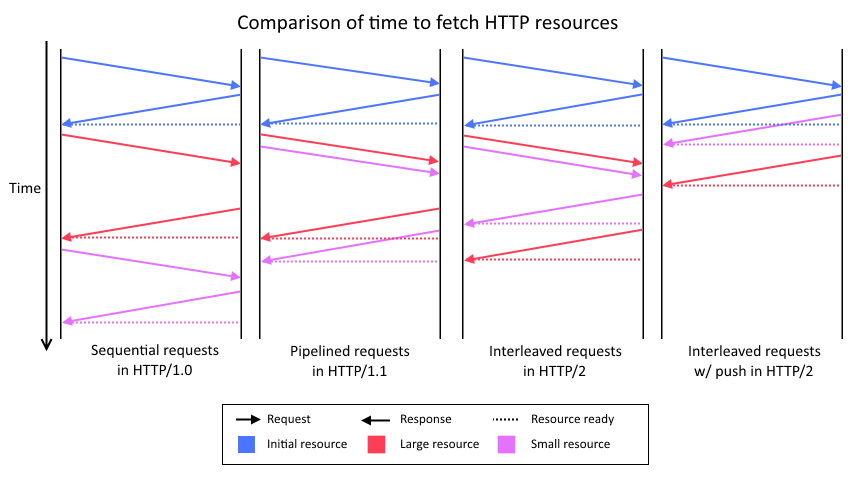
Figure 1. http timing diagram 출처
왜 HPACK입니까?
SPDY/2는 헤더 압축을 위해 각 방향으로 하나의 GZIP 컨텍스트를 사용하기로 제안했었습니다. 이것은 구현이 간단하면서도 효율적이었습니다.
그 이후로 암호화 내부에서 스트림 압축(like GZIP)을 사용하는데 대한 주요 공격에 대해서 문서화 되었습니다. CRIME
CRIME을 사용하면 데이터를 암호화된 스트림에 주입하여 일반 텍스트를 “probe” 하고 복구할 수 있습니다. 웹이기 때문에 JavaScript는 이를 가능하게 해주고, TLS로 보호 된 HTTP 자원에 CRIME을 사용해서 쿠기와 인증 토근을 복구하는 것을 시연했었습니다.
그 결과, GZIP 압축을 사용할 수 없습니다. 이번 케이스에 적합하고 안전하게 사용할 수있는 다른 알고리즘을 못 찾아서 coarse granularity한 환경에서 동작하는 헤더에 특화된 새로운 압축 방식을 만들었습니다. HTTP 헤더는 메시지간에 거의 변경되지 않기 때문에 압축이 효율적이고 더 안전합니다.
HTTP/2에서 쿠키(또는 다른 헤더)를 개선시킬 수 있습니까?
이러한 수고는 와이어 프로토콜의 개정에 대한 작업을 위해 승인되었습니다. 즉 HTTP 헤더, 메소드 등의 semantics을 변경하는 것이 아니라, 어떻게 “와이어에(onto the wire)”두는지를 확인하기 위함.
왜냐하면 HTTP는 널리 사용되고 있기 때문입니다. 새로운 버전의 HTTP를 사용하여 새로운 state 메커니즘을(논의 되고있는 하나의 예) 도입하고, core 메소드를 변경해서 (다행스럽게도 이것은 아직 제안되지 않습니다) 새로운 프로토콜이 기존의 Web과 호환되지 않습니다.
특히 HTTP/1에서 HTTP/2로 변경이 가능하고, 아무런 정보를 잃지 않고도 되돌릴 수 있게 하려고 합니다. 헤더의 “정리(cleaning up)”를 시작하면 (대부분의 경우 HTTP 헤더가 매우 지저분하다는 것에 동의합니다.) 기존 Web과 많은 호환성 문제가 있습니다.
이렇게하는 것은 새로운 프로토콜 채택을 반대하는 마찰만 불러일으킬지도 모릅니다.
그것은 HTTP Working Group에서 HTTP/2뿐만 아니라 모든 HTTP를 담당하고 있다는 것을 의미합니다. 따라서 이미 사용중인 Web과 호환되는한 버전에 의존적이지 않은 새로운 메커니즘을 만들어 낼 수 있습니다
non-browser HTTP 사용자는 어떻게 되나요?
non-browser 응용 프로그램에서도 이미 HTTP를 사용하는 경우는 HTTP/2도 사용할 수 있을 것입니다.
초기의 피드백은 HTTP/2가 HTTP “API”에 비교해서 뛰어난 성능을 가지고 있는 것입니다. 왜냐하면 API는 설계에서 request 오버 헤드 등을 고려할 필요가 없기 때문입니다.
그렇게 말해 왔듯이, 우리가 고려하고 있는 개선의 주된 초점은 전형적인 웹 브라우저를 사용한 사례입니다. 이는 프로토콜의 핵심적인 활용 사례이기 때문입니다.
이에 대해 우리의 charter 헌장에서는 이렇게 말합니다 :
규격의 결과로 일반적인 HTTP의 기존 배포, 특히 웹 브라우징(데스크톱, 모바일), 브라우저 이외의 사용자("HTTP APIs"),
웹 서비스(다양한 기업 콘텐츠 서비스) 그리고 중개(프록시, 기업의 방화벽, 역방향 프록시와 CDN에 의한) 이러한 목표를 충족할 것으로 예상됩니다.
마찬가지로, HTTP1.x같은 새로운 프로토콜에서 (e.g. 헤더, methods, 상태 코드, 캐시 지침)에 대한 현재와 미래의 semantic 확장이 지원되어야 합니다.
여기에는 지정되지 않은 동작(non-specified behaviours)이 필요한 경우에 대한 HTTP의 사용법은
(e.g. 타임 아웃 같은 연결 상태, 클라이언트 선호도(client affinity), 차단(interception) 프록시)의 포함되지 않습니다.
이러한 사용은 최종 product에서 사용 할수도/못 할수도 있습니다.
HTTP/2는 암호화가 필요합니까?
No.
광범위한 논의 끝에 Working Group은 새 프로토콜에 대한 TLS와 같은 암호화 사용을 필요로하는 의견일치에 이르지 못했습니다.
그러나 일부 구현(Implementations)들에서는 암호화 된 연결에 사용되는 경우만 HTTP/2를 지원한다고 했습니다 그렇지만 현재 어떠한 브라우저도 암호화되지 않은 HTTP/2를 지원하지는 않습니다.
여기까지 1차 번역 완료 아래부터 이어서
HTTP/2는 보안을 개선하기 위해 무엇을 할 것인가?
HTTP/2는 필요한 TLS 프로파일을 정의합니다. 여기에는 버전 암호화 스위트 블랙리스트 및 사용되는 확장 기능이 포함되어 있습니다.
자세한 내용은 사양을 참조하십시오.
또한 HTTP : // URL로 TLS를 사용하는 (이른바 ‘기회 적 암호화 “) 등의 추가 메커니즘에 대한 논의도 있습니다. RFC 8164을 참조하십시오.
지금 HTTP/2를 사용할 수 있습니까?
브라우저에서는 Edge / Safari / Firefox / Chrome 최신 버전에서 HTTP/2를 지원하고 있습니다. Blink에 따른 다른 브라우저는 HTTP/2 (예를 들어, Opera 및 Yandex 브라우저)도 지원한다. 자세한 내용은 캬니우스를 참조하십시오.
또한 여러 서버 (Akamai, Google, Twitter의 메인 사이트에서 베타 지원 포함) 및 배포하고 테스트 할 수있는 다수의 Open Source 구현이 있습니다.
자세한 내용은 구현 목록을 참조하십시오.
HTTP/2는 HTTP/1.x를 바꾸시겠습니까?
워킹 그룹의 목표는 HTTP/1.x의 전형적인 사용이 HTTP/2를 사용하여 몇 가지 이득을 볼 수 있다는 것입니다. 그러나 우리는 세계를 강제로 마이그레이션 할 수 없습니다. 또한 사람들이 프록시와 서버를 배포하는 방법에 대한 HTTP/1.x는 아직 상당한 시간 사용되고있을 수 있습니다.
HTTP/3이 있나요?
HTTP/2에서 도입 된 협상의 구조가 잘하면 이전보다 쉽게 새로운 버전의 HTTP를 지원하는 것입니다.
구현에 관한 질문
왜 HEADERS 프레임의 Continuation 주위의 규칙?
단일 값 (Set-Cookie 등)가 16KiB - 1을 초과 할 수 있으며, 하나의 프레임에 맞지 않을 수 있기 때문에 계속 존재합니다. 이를 해결하는 가장 오류가 일어나기 어려운 방법은 모든 헤더 데이터가 백투백 프레임에 제공되는 것을 요구하는 것이 었습니다. 따라서 디코딩 및 버퍼 관리가 쉬워졌습니다.
HPACK의 최소 크기 또는 최대 크기는 얼마입니까?
수신기는 항상 HPACK에서 사용되는 메모리의 양을 제어하고 SETTINGS 프레임의 최대 표현 가능한 정수에 대한 최대 값, 현재 2 ^ 32-1을 최소로 제로로 설정 할 수 있습니다.
HPACK 상태를 유지하지 않으려면 어떻게해야합니까?
SETTINGS 프레임 스테이트 크기 (SETTINGS_HEADER_TABLE_SIZE)를 0으로 설정 한 다음, ACK 비트가 세트 된 SETTINGS 프레임이 수신 될 때까지 RST는 모든 스트림을 전송합니다.
단일 압축 / 흐름 제어 문맥이 존재하는 이유는 무엇입니까?
단순.
원래 제안 스트림 그룹이 컨텍스트 흐름 제어 등을 공유했습니다. 프록시 (및 그것을 통해 사용자 경험)에게 유익하지만 그렇게하면 상당히 복잡했습니다. 우리는 간단한 것으로 시작해서, 그것이 얼마나 고통인지를보고, 향후 프로토콜 개정판에서는 통증 (있는 경우)를 해결하기로 결정했습니다.
HPACK에 EOS 기호가있는 이유는 무엇입니까?
HPACK의 허프만 인코딩은 CPU 효율성과 보안의 이유로 허프만 인코딩 된 문자열을 다음의 바이트를 패딩합니다. 특정 문자열에 필요한 0~7 비트의 패딩이 있습니다.
허프만 디코딩을 고립 감안할 때, 필요한 충전재보다 긴 기호는 작동합니다. 그러나 HPACK의 설계에서는 허프만 인코딩 된 문자열을 바이트 단위로 비교 할 수 있습니다. EOS 심볼의 비트가 패딩에 사용되는 것을 요구하여 허프만 코딩 된 문자열을 바이트 비교 동등성을 판정 할 수 있도록합니다. 이것은 많은 헤더가 허프만 복호화되지 않고 해석되는 것을 의미한다.
HTTP/1.1을 구현하지 않고 HTTP/2를 구현할 수 있습니까?
네, 대부분.
HTTP/2 over TLS (h2)의 경우 http1.1 ALPN 식별자를 구현하지 않으면 HTTP/1.1 기능을 지원할 필요는 없습니다.
HTTP/2 over TCP (h2c)는 첫 번째 업그레이드 요구를 구현해야합니다.
h2c 전용 클라이언트는 “*“의 OPTIONS 요청 또는 “/”HEAD 요청을 생성해야합니다. 이것은 매우 안전 구축이 간단합니다. HTTP/2 만 구현하고자하는 클라이언트는 101 상태 코드없이 HTTP/1.1 응답을 오류로 처리해야합니다.
h2c 전용 서버는 101의 고정 응답을 가지는 Upgrade 헤더 필드를 포함하는 요청을 받아 들일 수 있습니다. h2c 업그레이드 토큰이없는 요청은 업그레이드 헤더 필드를 포함 505 (HTTP 버전을 지원하지 않는) 상태 코드 거부 할 수 있습니다. HTTP/1.1 응답을 처리하지 않는 서버는 HTTP/1.1 연결 업그레이드 클라이언트가 요청을 다시 시도하도록 연결 선두를 보낸 직후에 REFUSED_STREAM 오류 코드 스트림 1을 거부해야합니다.
섹션 5.3.2 우선 순위의 예는 잘못된 있습니까?
스트림 B는 무게 4를 가지고 스트림 C는 가중치 12을 가진다. 이 스트림의 각 수신 가능한 자원의 비율을 결정하기 위해 모든 가중치 (16)을 합산하여 각 스트림 가중치를 총 무게로 나눈한다. 따라서 스트림 B는 사용 가능한 자원의 4 분의 1을 수신 스트림 C는 3/4을 수신한다. 결과적으로 명세서가 같이 스트림 B는 스트림 C에 할당 된 자원의 3 분의 1을 이상적으로 수신한다.
HTTP/2 연결 TCP_NODELAY가 필요하세요?
네, 아마. 단일 스트림을 사용하여 대량의 데이터 만 다운로드하지 클라이언트의 구현에도 최대 전송 속도를 달성하기 위해 반대 방향으로 되돌려 야하는 패킷 수 있습니다. TCP_NODELAY가 설정되어 있지 않은 경우 (Nagle 알고리즘을 여전히 허용하는 경우) 나가는 패킷 후 패킷과 병합하기 위해 잠시 유지됩니다.
이러한 패킷이 예를 들어, 데이터를 전송하는 데 사용할 수있는 창이 더 많은 것을 피어에 전달 패킷 인 경우, 그 송신을 여러 밀리 초 (또는 그 이상) 지연하는 것은 빠른 연결 심각한 영향을 미치고있다.
배치에 관한 질문
HTTP/2가 암호화되어있는 경우 어떻게 디버깅합니까?
응용 프로그램 데이터에 액세스하려면 여러 가지 방법이 있지만, 최근의 개발 버전에 포함되어있는 Wireshark 플러그인과 함께 NSS 키 로깅을 사용하는 것이 가장 간단합니다. 이것은 Firefox 및 Chrome에서 모두 작동합니다.
HTTP/2 서버 푸시는 어떻게 사용할 수 있습니까?
HTTP/2 서버 푸시는 서버가 요청을 기다리지 않고 클라이언트에 콘텐츠를 제공 할 수 있습니다. 이는 특히 네트워크 왕복 시간이 자원에 소요되는 시간의 대부분을 차지하는 대역폭이 넓은 지연 제품을 사용하여 연결하면 리소스를 검색하는 시간을 개선 할 수 있습니다.
요청 내용에 따라 다른 자원을 푸시하는 것은 현명하지 않습니다. 현재 브라우저는 일치 한 요구를 할 경우에만 푸시 요청을 사용합니다 (RFC 7234의 섹션 4 참조).
일부 캐시는 Vary 헤더 필드에 나열되어 있어도 모든 Header 필드 변형을 고려하지 않습니다. 푸시 된 자원이 받아 들여질 가능성을 최대화하려면 콘텐츠의 협상을 피하는 것이 좋습니다. accept-encoding 헤더 필드를 기반으로 콘텐츠 협상은 캐시가 널리 존중되지만 다른 헤더 필드도 지원되지 않을 수 있습니다.